
Okay, so yesterday I was messing around, trying to see how Caroline Garcia would do against Bernarda Pera. Just a little personal project, you know?
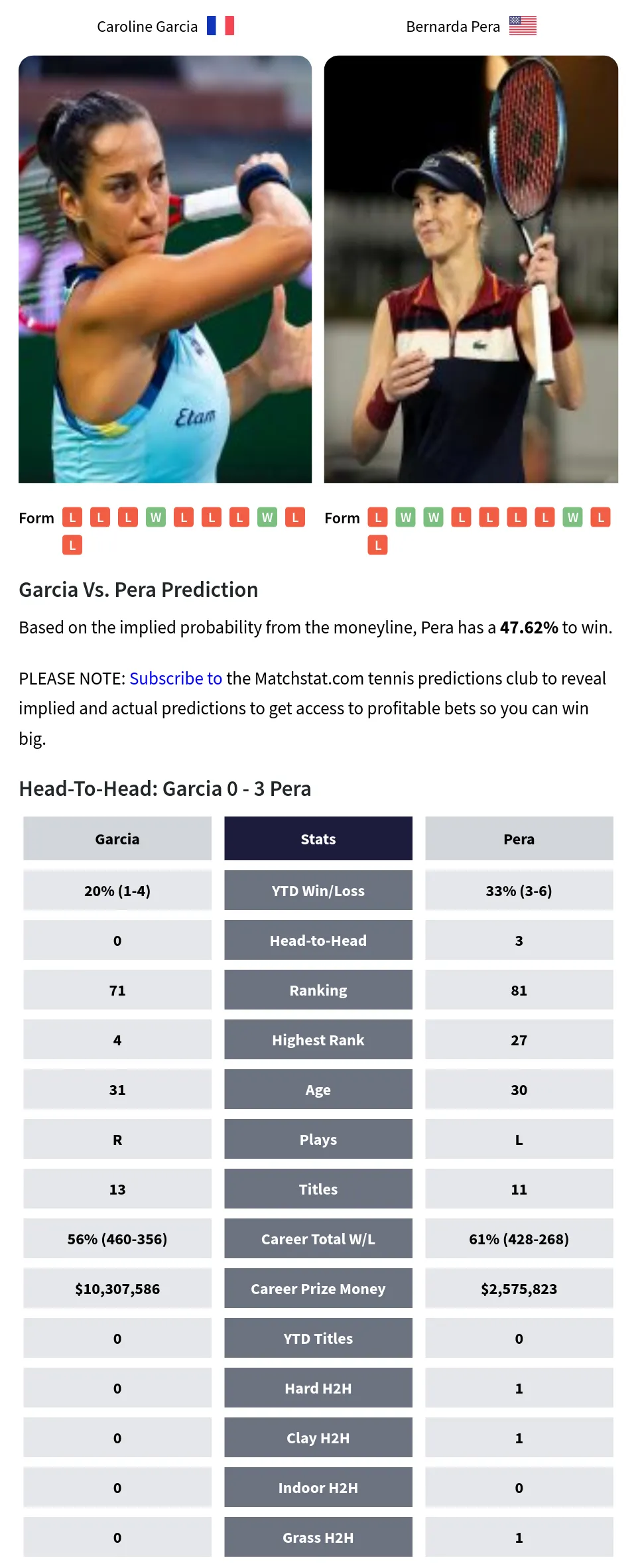
First off, I gathered some data. I hit up a couple of sports stats sites and grabbed their head-to-head records, recent performances, you name it. Just wanted to get a feel for their strengths and weaknesses. Nothing fancy, just the basics.


Then, I started thinking about how I could simulate a match. I figured I couldn’t predict every single point, but I could try to model their tendencies. Like, how often does Garcia hit an ace? What’s Pera’s break point conversion rate? I just threw that all into a spreadsheet.
Next, I tried to build a simple probability model. I used the data I collected to assign probabilities to different outcomes, like Garcia winning a point on her serve, Pera returning a shot deep, stuff like that. It was all pretty rough, just eyeballing it and tweaking things until it felt somewhat realistic.
After that, I wrote a little script in Python. Nothing too crazy, just a loop that simulated points based on the probabilities I assigned. I’d generate random numbers, compare them to the probabilities, and decide who won the point. Kept track of the score, obviously.
I ran the simulation like, a thousand times. Wanted to see how often Garcia won on average. The results were all over the place, but generally, Garcia came out on top more often than Pera, which kinda matched what I expected.
Lastly, I messed around with the probabilities a bit. I wanted to see what would happen if Pera improved her return game, or if Garcia started making more unforced errors. Just played around with different scenarios to see how it affected the outcome.
It was a fun little project, even though it was super basic. Learned a bit about data analysis and probability models along the way. Plus, it gave me something to do on a slow afternoon.





{kind=link}