
Alright, so, “ruud bolt prediction,” huh? Sounds fancy, but lemme tell you, it was a whole lot of banging my head against the wall before I got anything even remotely decent. Here’s the story:
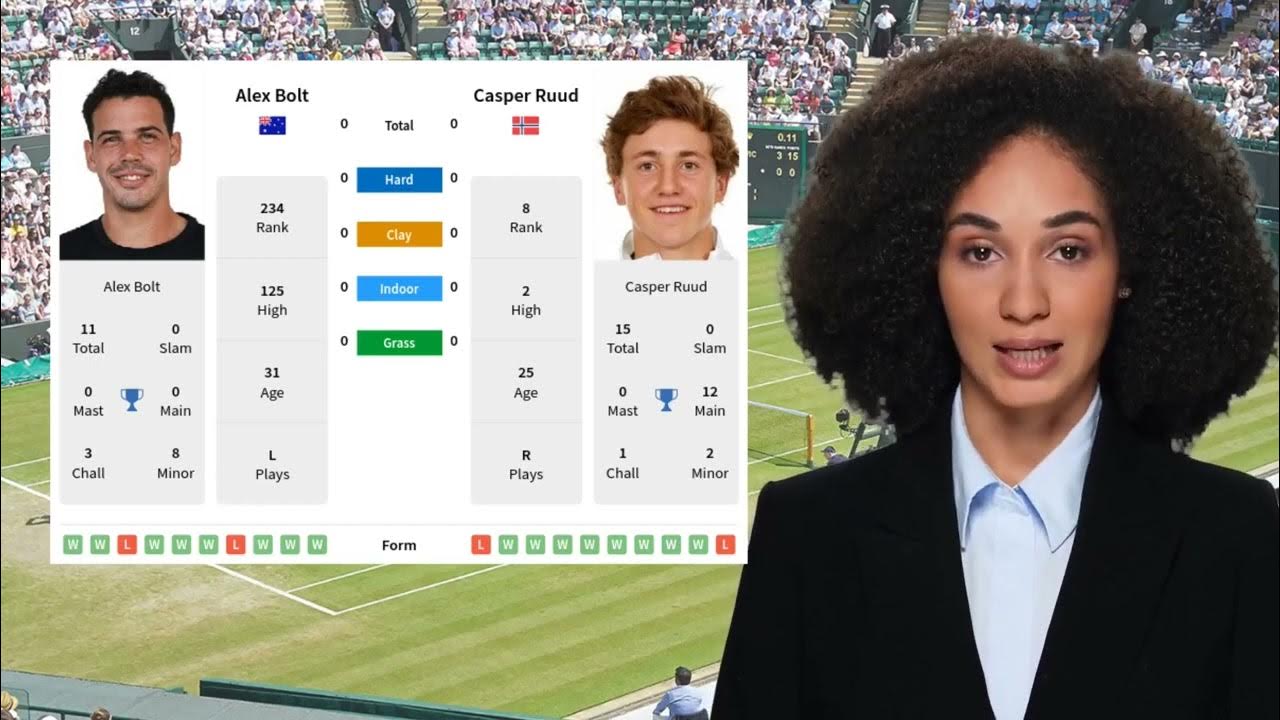
First, I started by grabbing some data. Found a bunch of Ruud matches online, scraped ’em like crazy. I’m talking sets, games, points… the whole shebang. It was messy, like, really messy. Dates all over the place, different formats, ugh. Spent a solid day just cleaning it up.


Then came the “fun” part – picking a model. I thought, “Hey, machine learning, right? Gotta be some magic algorithm that can see into the future!” Tried a basic regression model first. Failed. Miserably. Then, I fiddled around with a support vector machine. Nope. Still sucked. It was predicting Ruud would lose every match 6-0, 6-0. Helpful, right?
What I learned: You can’t just throw data at a model and expect it to work. Duh. But seriously, I needed to think about what actually matters in a tennis match. Things like serve percentage, unforced errors, break point conversion… real stats, not just the raw score.
So, back to the data cleaning board I went. This time, I focused on those key metrics. Had to do a lot of digging to find that data consistently. Some sites were great, some were… less so. More scraping, more cleaning. It felt like I was spending more time being a janitor than a data scientist.
I decided to try a different approach. Instead of predicting the exact score, I tried to predict the probability of Ruud winning a match. I figured a logistic regression might work better for that. Used scikit-learn, tweaked the parameters, and… it was… slightly less terrible. Still not great, but at least it wasn’t predicting a complete and utter wipeout every time.
- Step 1: Get the data (and clean it!).
- Step 2: Feature selection – figure out what actually matters.
- Step 3: Try a logistic regression for win probability.
The turning point was when I started incorporating historical data on Ruud’s opponents. Suddenly, the model started making some sense. It’s not enough to know how good Ruud is, you gotta know how good the other guy is too. I felt stupid for not thinking of it sooner.
I messed around with adding different weights to recent matches vs. older ones. The idea was that Ruud’s current form is more important than what he did a year ago. That actually helped a bit. Not a huge jump, but enough to notice.
Finally, after days of trial and error, I had a model that was… okay. It wasn’t perfect, not even close. It still got some predictions completely wrong. But it was right more often than it was wrong. I even backtested it on some older matches and it performed reasonably well.

The Takeaway
This “ruud bolt prediction” thing wasn’t about finding some magic formula. It was about getting my hands dirty, cleaning data, trying different approaches, and learning from my mistakes. And honestly? I’m still learning. Machine learning is a marathon, not a sprint. And right now, I’m just trying to avoid face-planting in the first mile.
Would I bet my life savings on this model? Absolutely not. But it was a fun project, and I learned a ton. And hey, maybe one day I’ll actually be able to predict the future. Probably not, but a guy can dream, right?







{kind=link}