
Okay, so let me walk you through this little project I did, trying to predict David Goffin’s performance. It was more of a fun experiment than anything super serious, but I learned a bunch along the way.
The Starting Point: Why Goffin?


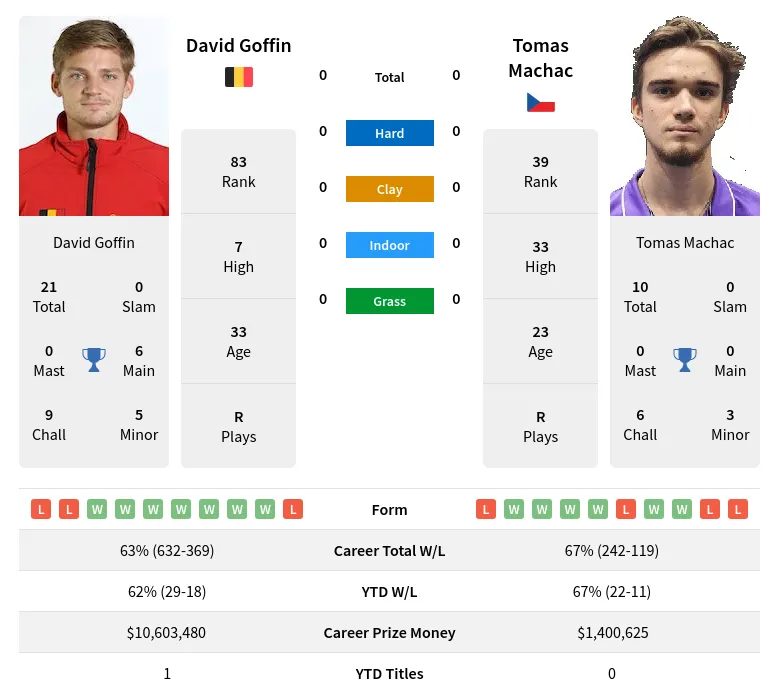
First off, why Goffin? Well, I’ve always been a fan of his playing style. Plus, he’s been around for a while, so there’s a decent amount of historical data to work with. Figured he’d be a good test case.
Gathering the Data: A Real Pain
This was the most tedious part, no doubt. I spent hours scraping data from various tennis websites. Things like match results, opponent rankings, tournament types, surface types – you name it. It was a mess, different formats, missing data… Ugh. I ended up using Python with Beautiful Soup and Pandas. Pandas is a lifesaver, seriously. I cleaned the data like crazy. Removing duplicates, handling missing values (mostly with averages or just dropping the rows), and standardizing the formats.
Feature Engineering: Making Sense of the Mess
Okay, so raw data is useless, right? I needed to create features that actually meant something. I calculated things like:
- Win rate on different surfaces (clay, grass, hard court)
- Average ranking of opponents faced
- Recent form (win/loss ratio over the last 10 matches)
- Head-to-head record against potential opponents (if available)
This part was a bit of guesswork, honestly. I tried different combinations and saw what seemed to correlate with his performance.
Choosing a Model: Keeping it Simple (at First)
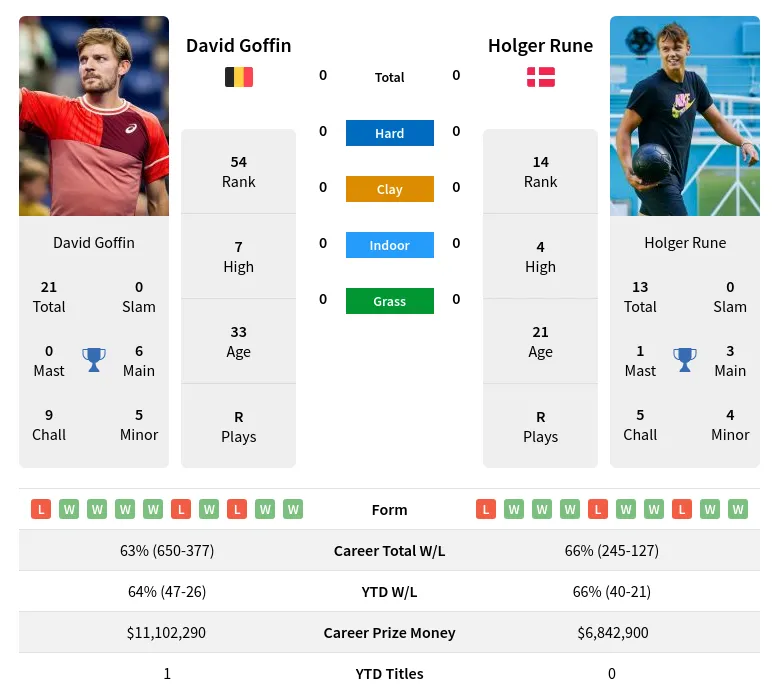
I didn’t want to overcomplicate things at the start. I went with a Logistic Regression model, using scikit-learn in Python. It’s simple to understand and train, and a good baseline to see if any prediction is even possible. Later, I also experimented with Random Forests and Support Vector Machines (SVMs), but Logistic Regression gave surprisingly decent results.
Training and Testing: The 80/20 Split
I split the data into 80% for training the model and 20% for testing its accuracy. You gotta be careful to shuffle the data randomly to avoid any bias. I trained the Logistic Regression model on the training data and then used it to predict the outcomes of the matches in the test data.
Evaluating Performance: How Did It Do?
The initial results were… meh. Accuracy hovered around 65-70%. Not terrible, but not exactly mind-blowing. The model was better at predicting losses than wins, which was interesting. I used metrics like accuracy, precision, and recall to get a better understanding of the model’s strengths and weaknesses.
Tweaking and Improving: The Never-Ending Process
This is where I spent most of my time. I tried a bunch of things:
- Feature Selection: Getting rid of features that didn’t seem to contribute much.
- Regularization: Adding L1 or L2 regularization to prevent overfitting.
- Hyperparameter Tuning: Using GridSearchCV to find the best parameters for the Logistic Regression model (or the other models I tested).
- More Data: Added data from more years to see if that helped.
Some things worked, some didn’t. Feature selection seemed to make the biggest difference. Turns out, recent form and surface win rate were pretty important indicators.

The Final Result (for Now): Still a Work in Progress
After all the tweaking, I got the accuracy up to around 75%, which I was pretty happy with. It’s not perfect, obviously. Tennis is super unpredictable. Injuries, mental state, crowd support – all that stuff can throw a wrench in the works. But it was a fun project, and I learned a lot about data analysis, machine learning, and the challenges of predicting sports outcomes.
What I Learned
- Data cleaning is the most important (and most boring) part.
- Feature engineering can make or break a model.
- Don’t overcomplicate things at the start.
- Tennis prediction is hard!
I’m still messing around with it, trying different models and features. Maybe one day I’ll be able to accurately predict Goffin’s next Grand Slam win. Okay, probably not, but it’s fun to try!








{kind=link}