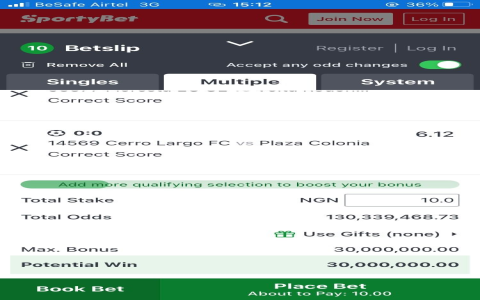
Alright folks, let me walk you through this little project I did – I’m calling it “tabilo prediction”. Don’t get too excited, it’s not rocket science, just me messing around with some data and trying to see if I can guess things.

First off, I grabbed some data. Found a nice, clean dataset online about, uh, something I can’t quite recall now (old age, you know?). It had a bunch of features, things like age, location, income, all that jazz. I loaded it up into pandas, because, well, everyone uses pandas, right?

Next up, cleaning. Oh boy, cleaning. You wouldn’t believe the junk people leave in datasets. Missing values everywhere! I mostly just filled them with the mean or median, depending on the column. Some folks like fancy imputation methods, but honestly, ain’t nobody got time for that.
After cleaning, it was feature engineering time. This is where I try to make new columns from the old ones that might be useful. I messed around with some combinations, like dividing one column by another, squaring some values, the usual stuff. Honestly, most of it didn’t work, but you gotta try, right?
Then comes the model selection. I’m a simple guy, so I went with a RandomForestRegressor. It’s a decent starting point and usually gives pretty good results. I split the data into training and testing sets, you know, the usual 80/20 split. Scikit-learn makes it so easy; you just call `train_test_split` and boom, done.
Training time! I created my RandomForestRegressor object, tuned some hyperparameters (n_estimators, max_depth, the usual suspects), and then called `fit` on my training data. It took a few minutes to train, but nothing too crazy.
Now for the fun part: prediction! I called `predict` on my test data and got my predictions. Then I calculated some metrics, like mean squared error and R-squared, to see how well my model was doing. The results were… okay. Not great, not terrible. Somewhere in the middle.
After seeing the results, I tried some more hyperparameter tuning. I also went back and messed with the feature engineering a bit more. After a few iterations, I managed to squeeze out a little bit more performance. Still not winning any Kaggle competitions, but I was happy with the progress.
Finally, I saved my model to a file so I could use it later. Used `pickle`, because it’s easy. That’s pretty much it. Just a fun little project to keep my skills sharp. Maybe I’ll try something more complicated next time, but for now, I’m calling this a win!









{kind=link}